**作者:**张景涛
数据中心网络的架构至关重要,它们通常分为两大类:一类是传统的通算网络,支撑着企业的IT系统、网站托管、电子邮件服务等常规计算任务;另一类则是智算网络,专为人工智能(AI)和机器学习(ML)任务设计,这些任务对计算能力和延迟有着更为严苛的要求,需要处理庞大的数据量并执行复杂的计算。
在智算中心的世界里,高效的网络互联是其强大计算能力的核心。这种互联可以分为两大类:**节点内(超节点内)互联(scale up)和节点间(超节点)互联(scale out)。**简单来说,节点内(超节点内)互联指的是超节点内部的处理器、加速器、其他外设以及存储设备之间的连接,而节点间(超节点)互联则是指不同服务器、超节点之间的连接。
目前,节点内(超节点内)互联主要采用的协议有PCIe、NVLink(英伟达)、Infinity Fabric(AMD)等等。这些技术虽然强大,但大多数都属于各自公司私有,开放性有限。与此同时,节点间互联则广泛使用IB和ROCEV2等协议,它们在开放性方面表现得更为出色。
网络带宽和延迟成为用于AI的Scale-up网络的重要因素。主要原因是单个GPU由于算力和存储的因素无法支持AI中大型语言模型的训练,所以需要GPU集群组成一个巨大计算单元,并通过一个高吞吐量的Scale up网络实现巨大计算单元内部互联。这个计算单元通常由数百到上千个GPU组成,并且随着模型的增大而继续增长。LLM训练性能越来越取决于这个scale up网络吞吐量。
而Scale out网络则是用于这些计算单元之间的互联,最终组成一个巨大、松耦合的集群。在主流的Scale Out网络中,目前主要使用ROCE和InfiniBand。另外超以太网联盟(UEC)正在推动Scale out网络技术的标准化。
AI训练的背景知识 #
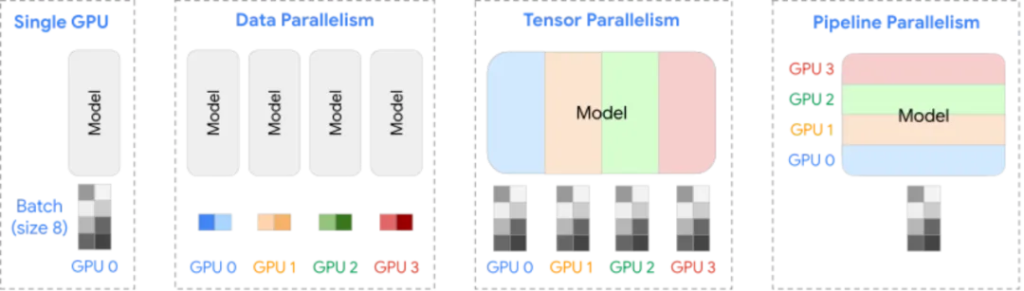
当前广泛应用于AI训练并行计算模式主要有以下三类:
- 数据并行:将不同的样本数据分配给不同的GPU,以加快训练速度;用在主机之间(Scale out网络)。
- 张量并行:将模型的参数矩阵划分为子矩阵,并分配到不同的GPU上,以解决内存限制并加速计算。一般用在主机内部(Scale up网络)。
- 流水线并行:将模型分为多个阶段,每个阶段分配给不同的GPU,以改善内存利用率和资源效率。一般用在主机之间(Scale out网络)。
Scale up网络的核心诉求 #
高带宽(TB/s 级) #
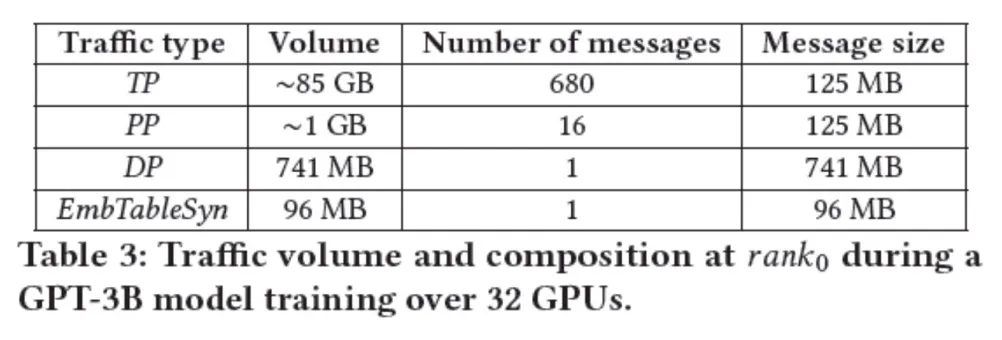
Scale-up网络承载的主要是张量并行的数据流量,为了让各位读者对不同网络流量模式有直观的认识,我引用了《Understanding Communication Characteristics of Distributed Training》论文中的一张表格,这个表格说明了GPT-3B的模型在32个GPU上进行训练时的流量统计。从这个表格可以看出,Scale-up承载的流量相比Scale-out流量有1-2个数量级的差异。
参见图3,Meta在一个演讲中也给出了LLM和Ranking应用的网络需求。
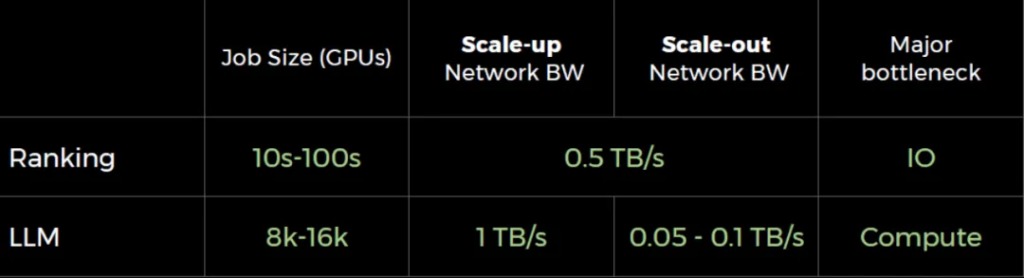
参考AI模型训练过程中的流量特点和业界主流技术的实现,Scale up网络带宽需要TB/s量级,这也是明显区别于Scale out网络的一个地方。
低时延(亚微秒级) #
Scale-up网络(也称为总线域网络,高带宽域网络HB),主要目标是追求极致性能,允许AI加速器直接访问其他AI加速器的存储器,对时延要求极高。为满足AI加速器的本地内存访问时延低于100纳秒,网络访问时延需控制在亚微秒。网络设计需紧密结合业务,省略传统网络的传输层和网络层,通过信用机制和链路层重传确保可靠性。现有基于PAM4调制和112Gbps、224Gbps SerDes技术的电互联对低时延构成挑战,静态时延较高(20ns左右),且现有FEC方案在100Gbps速率下引入显著时延(预计引入100ns左右时延),需探索新的信道编码方案以满足性能要求。
CXL是否可以作为一个备选技术 #
随着UALink联盟的成立并在可预见的未来大概率会成为Scale up网络标准之一,CXL作为Scale up网络技术的可行性则明显存在疑问。CXL标准与Infinity-Fabric存在相同的性能问题,因为它基于PCIe标准相比以太网serdes在带宽密度方面具备明显的劣势(参考表1 AMD、NVIDIA互联技术指标对比)。这也是为什么专有的基于以太网Serdes的接口在AI Scale up技术中占据主导地位的原因之一。一些初创公司正在试图通过CXL over Ethernet、chiplet和光互联技术来解决这个问题。
CXL的另一个问题是以CPU为中心的数据流,它与目前业界主流以加速器为中心和以数据为中心的计算架构演进趋势明显相背。另外基于PCIe的分层树形拓扑给CXL交换实现带来了不必要的复杂性。
CXL对于CPU生态系统、内存数据库和大数据工作流等工作负载仍然很重要。CXL可能会成为包括AI训练任务在内的所有工作流的内存扩展技术。
总而言之,CXL在AI中的主要作用是实现内存扩展,而不是直接进行GPU到GPU的通信来进行大规模AI训练。
基于以太网的Scale up技术 #
在当前的Scale-up技术领域,主流解决方案基于总线协议,并借鉴网络技术以增强其可扩展性,从而支持更多的节点。然而,Intel的Gaudi采取了一种创新的方法,利用RoCE V2技术进行Scale-up互连。与此同时硅仙人Jim Keller提倡使用以太网替代NVLink,这一提议在他的公司Tenstorrent得到了巧妙的应用,通过以太网实现了芯片间网络的互连。
基于以太网的Scale-up技术与基于总线的Scale up技术本质上的差异,可以被视为一种哲学和理念上的选择:在协议的实现上到底是做加法还是做减法?这种选择完全取决于各个厂商自己的技术与商业考量,并无绝对的优劣之分。
基于以太网的Scale-up技术需要解决以下关键问题:
**内存语义支持:**必须在现有的verbs接口上增加基于load/store/atomic的内存语义的支持,这是Scale-up互连技术的核心需求。
**降低延迟与抖动:**在AI训练等场景中,相比于绝对延迟,延迟的一致性(即抖动)更为关键,因为训练迭代的完成时间取决于最后一条消息的接收。为此,需要在标准RoCE协议的基础上进行定制化设计,例如通过协议层融合、扩展现有协议字段等方法来降低实现复杂度和简化协议路径。同时需要从现有以太网技术中静态和动态延迟问题中吸取教训,进行针对性的改进,如通过扩展协议字段实现交换侧的基于端口的路由,优化转发队列设计等。
在进行这些修改的同时,更重要的是确保新的协议实现与现有协议和硬件保持最大程度的兼容。这样做可以充分利用现有的以太网软硬件生态系统,从而降低协议部署和后续维护的成本。
AI Scale up底层通信技术 电 or 光 #
底层通信技术的选择需要综合考虑距离、功耗、密度、串扰、成本。Scale up互联技术在统一物理地址空间内将多GPU 组成一个超节点,随着大模型参数的快速提升,扩大Scale up 域有助于张量并行效率的提高。
下面从英伟达产品的角度来分析一下底层通信技术的选择过程。NVLINK 是英伟达GPU 实现Scale up 的主要通信方式,其通过NVLINK Switch 实现节点内高速交换。NVLINK Switch 3 最高连接8 片GPU,而NVLINK Switch 4 最多可扩展到576 个,GB200 NVL72、NVL36*2 的Scale up 域为72 个GPU。在8 颗GPU 互联时,NVLINK 主要通过PCB 进行intra-board 通信,距离通常在1 米内;而72 颗GPU 互联达到了机架内部、相邻机架间通信,距离通常在1 米至5 米,因此距离成为GB200 选择铜缆互联的最主要因素。
除此之外,与光通信(AOC、CPO)对比,铜缆的成本仅为AOC 的十分之一,虽然CPO 在功耗、密度、距离都更有潜在优势,但当前产业链还不成熟,尤其涉及到客户机房改造、服务器设计等其他附加开销,这些都会大大增加系统的总体拥有成本。
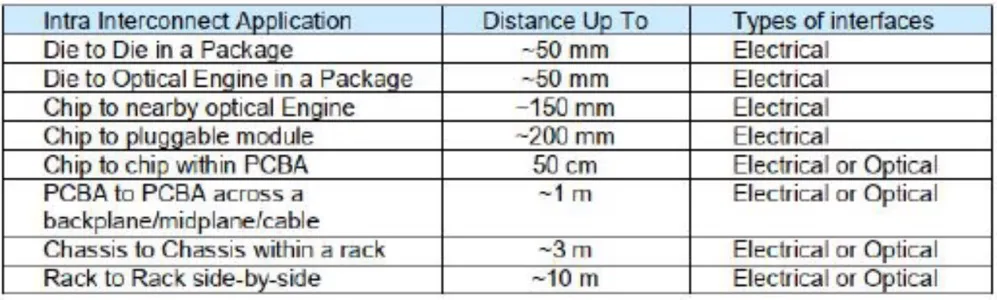
底层线缆的选择需要根据具体的应用场景、技术需求和成本效益进行综合考量。在短距离和成本敏感的应用中,铜缆可能是更合适的选择;而在长距离、高带宽和高密度部署的场景中,光纤可能更具有优势。随着技术的不断进步和产业链的成熟,未来可能会有新的线缆技术出现,为智算场景下的Scale-up互联提供更多的选择和优化空间。
业界主流Scale up物理层技术对比 #
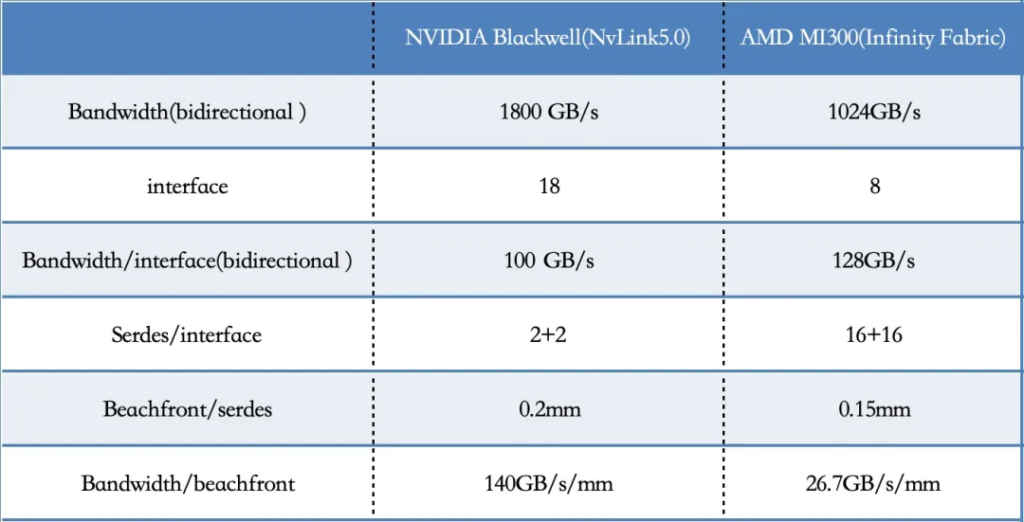
从上面表格可以看出与AMD Infinity Fabric相比,NVIDIA NVLink 5在带宽效率(bandwidth/beachfront)方面具有约5倍的优势。另外表格中涉及到beachfront都属于估算,具体会随着工艺节点和不同serdes IP厂商有所变动,尽管预计在未来1-2年内,AMD的infinity fabric技术互联带宽会翻倍,达到每通道64Gbps,但是相比而言,NvLink仍然具备2-3倍左右的带宽效率优势。
国内外Scale up标准联盟 #
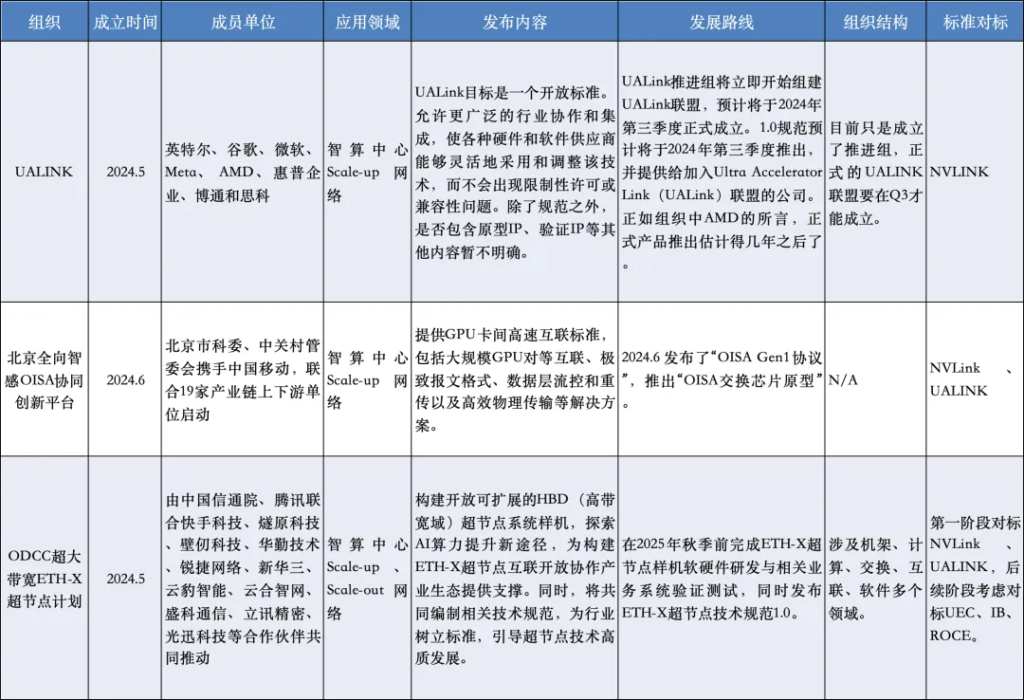
私有协议 VS 开放标准 #
私有协议的定制实现往往能超越标准产品的性能(比如目前的NVLINK就具备全方位的碾压优势),这是因为公开标准制定过程中需要投入大量时间和努力,并且还要在标准成员间进行技术和非技术因素的协调与博弈。然而标准组织正通过采纳更加灵活的流程设计和快速响应需求来应对这一挑战,包括实时更新文档等方式,以确保技术与时俱进。尽管如此,对于开放系统而言,要持续保持性能领先仍是一件非常不容易的事情。
全新的标准联盟还拥有一个显著优势,那就是它不受现有技术向后兼容的限制。新标准有机会实现跨越式发展,超越现有技术,借助联盟的集体智慧,打造强大的生态系统。NVMe标准的制定过程便是一个典型例子,在Amber Huffman的领导下,它取得了显著的性能提升。道阻且长,行则将至,希望Scale up技术相关的各种国内外联盟在富有智慧和领导力的组织者带领下也能实现这样的飞跃。
此外,对系统非性能方面的标准化(例如OAM规范、通信协议、软件API/接口以及像PyTorch这样的软件生态系统)同样至关重要。我个人是开放标准的绝对拥趸,因为我深信一个理念“独行者步疾,结伴者行远”。
参考文献:
- 《一文揭秘AI智算中心网络流量 – 大模型训练篇》
- 《Leading with open Models, frameworks, and systems》
- 《Understanding Communication Characteristics of Distributed Training》
- 《智算网络中Scale-out网络和Scale-up网络的本质区别是什么?》
- 《万字干货!手把手教你如何训练超大规模集群下的大语言模型》
- 《英伟达、谷歌、Meta等5大巨头Scale-up超节点规模大比拼,揭示未来AI网络最优解》
- 《谈谈基于以太网的GPU Scale-UP网络》
- 《GB200 引爆高速铜互连,探寻AI 时代短距高密通信“最优解”》