这篇文章,我们主要解决两个问题。第一,如何使用套接字接收和发送数据,第二,实现一个自己的读写Buffer。
在Linux操作系统中,常用来使用套接字接收和发送数据有两组方法
发送数据
ssize_t send(int sock_fd, const void *buf, size_t len, int flags);
ssize_t write(int sock_fd, const void *buf, size_t count);
send方法有四个参数
- sock_fd:是网络套接字
- buf:是要发送的数据
- len:表示要发送的数据大小,send函数发送最多不超过len大小的字节
- flags:用于控制发送的行为,这个我们用到的时候再说,默认传0
最后,返回值是ssize_t,表示实际发送成功的字节数。返回-1表示出错。
在Linux操作系统中,套接字也可以理解为是一种特殊的文件。所以,套接字发送数据也可以使用write函数,其有3个参数
- sock_fd:是套接字
- buf:是要写入的内容
- count:是最大写入多少字节
这里要注意,当套接字为阻塞模式的时候,如果发送缓冲区无法容纳发送的数据,程序会阻塞在send和write方法。
读取数据
ssize_t recv(int sock_fd, void *buf, size_t len, int flags);
ssize_t read (int sock_fd, void *buf, size_t count);
recv函数,有四个参数
- sock_fd:从哪个套接字接收数据
- buf:接收到的数据保存buf中
- len:本次最多接收多少字节的数据
- flags:控制套接字接收的行为,这个后面遇到的时候再说,默认传0
返回-1表示出错,可以在errno取到对应的错误信息。如果是大于0表示实际读取到的字节数。如果是等于0(EOF)表示对端没有更多数据发送了,可能对端已经把连接关闭了。
read函数,和write一样,read也是Linux标准IO中操作文件的一个函数。有三个参数
- sock_fd:从哪个套接字接收数据
- buf:将读取到的数据保存在buf中
- count:最多读取多少字节的数据
如果返回0(EOF)表示对端没有数据可发送了,对方可能已经关闭了连接。返回-1表示失败。如果返回值大于0表示实际读取到的字节数。
在套接字阻塞模式下,如果调用read和recv函数的时候,套接字没有数据可读,程序会阻塞在read或者recv函数这里,直到有数据可读。
除了上面两对函数之外,其实套接字的读写还有一些其它的方法,比如sendmsg、recvmsg、sendfile、splice以及 用于UDP的sendto和recvfrom等。由于篇幅有限,本文只选取了基于TCP协议的两对读写函数。如果你对UDP或者其它的API有兴趣,可以自行研究一下。
send函数发送数据示例
char buf[1024];
while(1) {
memset(buf, 0, sizeof(buf));
fgets(buf, sizeof(buf), stdin);
send(sock_fd, buf, sizeof(buf), 0);
}
这段代码,先声明一个buf字符数组,在一个循环里不断从命令行读取用户的输入,然后将读取到的内容通过套接字发出去。
write函数发送数据示例
char buf[1024];
while(1) {
memset(buf, 0, sizeof(buf));
fgets(buf, sizeof(buf), stdin);
write(sock_fd, buf, sizeof(buf));
}
这段代码和上面一样,只不过是将send函数换成了write。
recv函数接收函数示例
while(1) {
socklen_t cli_len = sizeof(client_addr);
memset(&client_addr, 0, sizeof(client_addr));
int fd = accept(sock_fd, (struct sockaddr *)&client_addr, &cli_len);
if (fd < 0) {
perror("accept error");
exit(1);
}
bzero(buf, sizeof(buf));
int ret = recv(fd, buf, sizeof(buf), 0);
if (ret < 0) {
perror("recv error");
exit(1);
}
if (ret == 0) {
printf("client closed \n");
close(fd);
continue;
}
printf("recv: %s\n", buf);
}
这段代码,在一个循环中,不断的accept出客户端的连接套接字。如果accept返回的套接字小于0表示出错了。
接着使用recv函数从返回的套接字中接收数据,我们判断了recv的返回值,如果小于0表示出错了。如果等于0表示对端可能已经关闭了连接。所以,这里我们也要将套接字关闭,最后,将接收到的数据打印出来。
read函数接收数据示例
while(1) {
socklen_t cli_len = sizeof(client_addr);
memset(&client_addr, 0, sizeof(client_addr));
int fd = accept(sock_fd, (struct sockaddr *)&client_addr, &cli_len);
if (fd < 0) {
perror("accept error");
exit(1);
}
bzero(buf, sizeof(buf));
int ret = read(fd, buf, sizeof(buf));
if (ret < 0) {
perror("recv error");
exit(1);
}
if (ret == 0) {
printf("client closed \n");
close(fd);
continue;
}
printf("recv: %s\n", buf);
}
这段代码和上面recv是一样的,只不过我们将recv换成了read函数。
发送缓冲区 #
当我们调用send、write函数向套接字发送数据的时候,函数调用完并不表示数据就已经发送出去了,在现代操作系统中,网络协议栈都有一个发送缓冲区,调用send、write函数会先将数据拷贝到发送缓冲区,然后网络协议栈会将发送缓冲区的数据通过网卡驱动转为电信号给发送出去。
在阻塞模式下,当发送缓冲区空间不够,程序会阻塞在send、write函数(这个前面我们有简单提到), 直到发送缓冲区的数据发送出去腾出空间,将剩下的数据再拷贝到刚刚腾出来的空间里,如此往复,直接到数据全部拷贝进发送缓冲区,函数返回。
所以,当我们调用send、write函数之后,我们是不能保证数据一定就发出去了,此时,数据有可能还在发送缓冲区。
上面的代码我打了tag:v1.7。
接收缓冲区 #
和发送缓冲区一样,操作系统内核的网络协议栈也有一个接收缓冲区,当网卡收到对端传过来的电信号之后,网卡驱动将电信号解码转成对应的数据保存在接收缓冲区。
应用程序调用read、recv函数的时候,实际上是从接收缓冲区读取数据。所以,我们不能保证每次调用read、recv函数时一定能读出所有的数据。因为,数据可能还在对端的发送缓冲区,也可能还在各个中间设备(路由器、交换机、电信主干网线上等等)
在接收缓冲区中有一个读指针和一个写指针,当调用read和recv函数的时候,相应的读指针会往后移动,下次读取就会从新的读指针处开始读,而读指针移动的长度就是read和recv函数返回的实际读取到的字节的长度。
这对于已经有网络编程经验的人来说是理所当然的。但是,我相信对于没有接触过网络编程的人来说,对于这点大概率是会有困惑的。比如,希望在两个线程里从同一个套接字里读取相同的数据就是不行的,A线程读了之后B线程再去读的时候,A读走的那部分就没了。
数据流 #
上文中read和recv的示例代码其实是存在问题的,我们在recv和read的时候,只调了一次,最多只能读取1024字节的数据。而且我们说调用read和recv的时候并不能保证一定能读到所有的数据。
原因在于,TCP是流式协议。假如,我们要将下面的数据发送给对端
hello tcp server
最终可能不像我们想象的那样,一次性将数据发出去。更多的可能是数据被拆成了好几份。比如像下面这样:
第一次
hello
第二次** **
tcp server
数据被拆成了两段,第一次发送了hello,第二次发送了tcp server。你看,如果我们期望一次性读到完整的"hello tcp server"就不能实现了。
在TCP协议中,数据以字节流的方式传输,被发送的数据很可能不是一次性就能发完的,而很大可能会是被拆成了很多个小段,一段一段发出去。但是有一个重要的前提,就是TCP协议可以保证数据的顺序性。也就是以"hello tcp server"发出去,对端收到的就一定也是"hello tcp server",而不可能是"server hello tcp"。
你可能会问,如果第二次"tcp server"先到,“hello"一直没到怎么办呢?如果是"hello"丢了,或者超时了,会触发重传。接收端会一直等,等"hello"到了之后才会往接收缓冲区写。只有往接收缓冲区写了之后程序才可以接收到数据,此时的数据一定是有序的。
这个过程还是有一点点复杂,我在为什么说TCP是可靠的网络传输协议?这篇文章有非常详细的说明。如果你对TCP怎么保证数据的顺序感兴趣可以去看一下。针对这个问题,我们修改一下上面的代码。如下:
while(1) {
...
while (1) {
ret = read(fd, buf, sizeof(buf));
if (ret < 0) {
perror("recv error");
exit(1);
}
if (ret == 0) {
printf("client closed \n");
close(fd);
break;
}
printf("recv: %s\n", buf);
}
}
我们将read放在一个while循环里,一直读。当没有数据的时候,这段代码会阻塞在read调用。当有数据的时候,就会被拷贝到buf中,read函数返回。这样,我们就能源源不断的从套接字里读数据了。
到这里,你应该有一种感觉,就是对端源源不断的把数据发过来,我怎么知道对方想表达什么呢?
比如,对方想要上传一个文件。它上来就把文件读出来从第一个字节传到最后一个字节。我们怎么知道到什么时候结束?这个文件有多大呢?
要解决这个问题,我们就要做一些约定。比如,我们可以约定前面4个字节表示文件的长度,4个字节后的内容都是数据,读完指定长度的数据之后,我们就知道数据已经读完了。如果想表示更多的信息。比如除了长度之外我们还要指定4字节版本号,1字节类型。我们可以定义像下面这样的数据格式:1024V1.01DATA….
其中,1024表示实际数据的长度,V1.0表示接口版本,1表示消息类型,DATA表示实际的数据。这样,我们每次都是先读4个字节出来拿到数据长度,再读4个字节拿到版本号,再读1字节拿到类型,最后,我们读取指定长度那么多个字节就表示读完一条消息了。此时,我们再回到一开始,再读4节点拿到数据长度,如此往复。
还有一种方式,就是使用分隔符,比如HTTP协议就是这种方式最经典的实现
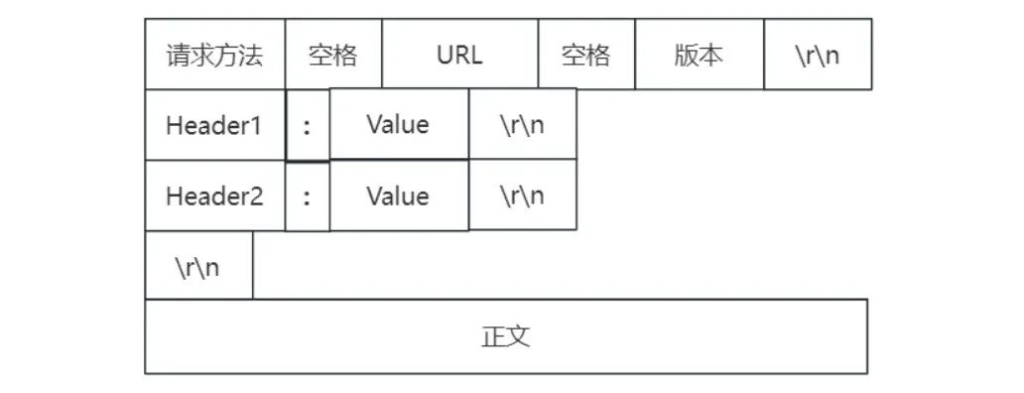
我们看到,HTTP使用\r\n来分隔数据。当然,你也可以定义自己的分隔符来约定自己的协议。但要注意的是,我们的正文中是不能包含分隔符的,否则就会产生冲突。
异常处理
上面的例子中,我们都是假定服务端和客户端运行起来之后不发生异常。假如对端系统崩溃了或者网络突然中断了,这时候是没有FIN包发过来的。所以,会一直阻塞在这里得不到执行。通常分两种情况
第一,对端没有FIN包
对端没有FIN包发出来的情况下,大致又可以分为以下两种情况
网络中断导致的
如果路由器发出了ICMP,可以探测到主机不可达。如果再调用read或者write返回Unreachable
如果路由器没有发出ICMP,又分两种情况:
- 如果此时阻塞在read函数,是无法感知到异常的,程序会一些阻塞在read函数。
- 如果先调用write,然后阻塞在read函数,网络协议栈会尝试将发送缓冲区的数据发出去,重试大概12次,9分钟左右。重试不成功网络协议栈会将连接标记为异常。read函数会返回TIMEOUT,如果继续调用write会立即失败。
系统崩溃导致的
这种情况和网络中断的处理是一致的,唯不一样的是。如果是断电重启,原来的数据包又来了,会返回RST。如果是阻塞套接字,read会立即返回Connection Reset错误。如果write会收到SIGPIPE信号。解决办法
对于阻塞套接字,没有比较好的方法解决,不过套接字有一个设置项,可以给read设置一个超时时间,例如:
struct timeval tv;
tv.tv_sec = 5;
tv.tv_usec = 0;
setsockopt(connfd, SOL_SOCKET, SO_RCVTIMEO, (const char *) &tv, sizeof(tv));
...
int n = recv(...)
if (n == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
...
}
}
对于非阻塞套接字来讲,会简单一些。下一篇文章讲非阻塞套接字的时候再详细说明。
第二,对端有FIN包
如果对端发出了FIN包的情况下,一般认为是对端正常的关闭连接,可能是调用了close、shutdown函数,或者是程序崩溃。read和write的现象如下:
read接收完数据之后,会返回一个EOF也就是返回值为0
write会得到一个peer connection closed错误,可以在errno中读取到,同时会触发信号SIGPIPE.
实现自己的Buffer
上面我们提到了HTTP协议,你可以试着按照HTTP协议的格式尝试自己解析一下HTTP协议的数据。如果没有接触过网络编程,这段程序写出来并不容易。下面我给出一段解析HTTP协议内容的代码:
size_t read_line(int fd, char *buf, size_t size) {
size_t i = 0;
ssize_t n;
char c = '\0';
while((i < size) && (c != '\n')) {
n = recv(fd, &c, 1, 0);
if (n > 0) {
if (c == '\r') {
n = recv(fd, &c, 1, MSG_PEEK);
if ((n > 0) && (c == '\n')) {
recv(fd, &c, 1, 0);
} else {
c = '\n';
}
}
buf[i] = c;
i++;
} else {
c = '\n';
}
}
buf[i] = '\0';
return i;
}
这段代码是 C语言最最最核心语法 这篇文章中拿过来的。这段代码每次读取一个字符,然后比对是否是’\r’和’\n’。如果不是’\r’和’\n’就放到buf中。这里有一个小技巧,就是使用recv的第四个参数传入MSG_PEEK,表示看一下当前这个位置是啥内容,不会清除缓冲区(读指针不移动),不影响下次读取。
如果你有一些操作系统知识,就一定知道程序在操作系统中运行起来之后,会有内核态和用户态。当我们的程序进行系统调用的时候,就会从用户态切换到内核态,内核态执行完之后再切换到用户态。这个切换是非常低效的,而recv函数就的调用就会切换用户和内核态。所以,上面这段程序是低效的。
解决这个问题也很简单,我们可以一次性多读一些数据出来。然后遍历读出来的数据,处理完之后,再去套接字里读一批出来。这样就可以减少内核态和用户态的切换,比如像下面这样:
char buf[1024];
int i = 0;
while(1) {
int ret = recv(sock_fd, buf, sizeof(buf), 0);
for (i = 0; i < ret; i++) {
// 在这里判断buf[i]是否是'\r'和'\n'
}
}
可以看到,这里我们一次性读取尽量多的数据,然后再去遍历读取到的数据,由于对数据的遍历都是在用户态完成的,这样就避免了频繁用户态和内核态的切换。但如果你仔细想想这段代码其实并不是很好写,因为没有了MSG_PEEK,不过你可以尝试着实现一下。
很多时候,上面的代码已经可以满足需求了。但是,上面的代码有几个问题。我们将HTTP协议和buf绑死了,如果再来一个根据长度+版本+类型+数据这种协议,我们就需要再重新根据这种协议实现一遍。
所以,大家就想是不是可以把数据读与写给封装起来,和业务无关。这就是你在很多系统中都能见到的一种实现,也就是接下来要介绍的Buffer。首先,我们定义Buffer的数据结果,如下:
struct buffer {
char *data; // bufer data
int r_idx; // read index
int w_idx; // write index
int size; // buffer size
}
其中,data用来保存读取数据的字符数组。r_idx表示当前读取到的位置,w_idx表示当前写的位置,size表示Buffer的大小。
创建Buffer
struct buffer *new_buffer() {
struct buffer *buf = malloc(sizeof(struct buffer));
if (!buf) {
return NULL;
}
buf->data = malloc(BUFFER_SIZE);
memset(buf->data, 0, BUFFER_SIZE);
buf->r_idx = buf->w_idx = 0;
buf->size = size;
return buf;
}
首先,我们使用malloc为Buffer申请一块内存空间,要注意的是,这里分配的空间,其中data分配的是char *指针的大小。为了保存读取到的数据,我们还要为data分配空间,这个空间的大小我们定义在了BUFFER_SIZE宏中。
初始状态,r_idx和w_idx都在0的位置。
这样,一个buf就创建好了,最后将创建好的buf返回。
往Buffer填充数据
int buffer_append(struct buffer *buf, char *data, size_t len) {
if (buf->size - buf->r_idx == buf->w_idx) {
return 0;
}
size_t write_size = 0;
size_t write_total = 0;
while(1) {
if (buf->size - buf->r_idx == buf->w_idx
|| write_total == len) {
break;
}
if (buf->r_idx > buf->w_idx) {
write_size = buf->r_idx - buf->w_idx;
} else if (buf->size - buf->w_idx < len) {
write_size = buf->size - buf->w_idx;
} else {
write_size = len;
}
memcpy(buf->data + buf->w_idx, data, write_size);
if (buf->w_idx + write_size < buf->size) {
buf->w_idx += write_size;
} else {
buf->w_idx = 0;
}
write_total += write_size;
}
return write_total;
}
我们实现的是一个环型Buffer,当剩下的空间写满了之后(也就是w_idx == size的时候),我们将w_idx置为0,从头开始再次尝试写入。
程序一进来我们判断读和写的位置是不是重叠了,如果重重叠了,我们就不能往里写了,并返回-2用来表示Buffer已经写满了。
你可能在很多场景下会看到环形Buffer的实现中,如果没来得及读,数据会被覆写。但我们这里,不能覆写,因为数据已经从套接字读出来了,我们不能丢。所以,在上层的业务处理上我们要判断如果返回-2表示Buffer已经满了,需要停下来先把已经存在的数据读出来。
接着,定义了两个变量write_size和write_total,分别表示当前这一次要写入的字节数和总共写入了多少字节数。
紧接着是一个循环,这是因为,如果Buffer剩余的空间如果不足以写入当前的数据,写指针w_idx需要回到0的位置再次尝试写入。这里要注意两种情况:
第一,当读指针r_idx在写指针w_idx右边的时候,r_idx的右边是不能写入的,因为这部分数据还没被取走,如果直接写入数据会被覆盖。所以,这种情况下,开始写的的位置是w_idx,实际可以写入的字节数是r_idx-w_idx。最后,相应的w_idx要加上实际写入的字节数。
第二,当读指针w_idx到buffer的结尾的长度不足以写入当前数据的时候,实际可写入的字节数是size-w_idx。写完之后,w_idx置0,再次从0开始尝试写入。
当w_idx到buffer结尾的长度足以容纳写入的数据时,实际写入的字节数就是传入进来的len。写完之后,w_idx加上len。
通过上面的分析,这种实现方式,当w_idx到buffer结尾的长度不足以容纳要写入的数据的时候,最坏的情况下,我们要循环两次才能把数据写进buffer,第三次循环的时候才会break。
你可以思考一下,有没有什么办法可以去掉这个while循环。比如我们去遍历要写入的字符数组,使用取模的方式来动态寻找w_idx索引,然后再把对应的字符写到w_idx中去。如果有兴趣可以实现一下,并比较一下两者的性能差异。
从套接字读
int buffer_read_from_socket(struct buffer *buf, int sock_fd) {
if (buf->size - buf->r_idx == buf->w_idx) {
return -2;
}
int read_size = 0;
if (buf->r_idx > buf->w_idx) {
read_size = buf->r_idx - buf->w_idx;
} else if (buf->size - buf->w_idx < BUFFER_SIZE) {
read_size = buf->size - buf->w_idx;
} else {
read_size = BUFFER_SIZE;
}
int ret = recv(sock_fd, buf->data + buf->w_idx, read_size, 0);
if (ret > 0) {
if (buf->w_idx + ret < buf->size) {
buf->w_idx += ret;
} else {
buf->w_idx = 0;
}
}
return ret;
}
这个方法是一次尽量多的从套接字读取数据到Buffer中,前面有提到过,recv和read函数每次调用都会有用户态和内核态的切换。我们要尽量少的调用这两个方法。
所以,最好的方法就是一次尽可能多的从套接字把数据读出来。你可能会说,我直接声明一个大的char字符数组去读就行了,为什么要搞得这么麻烦呢?比如:
char buf[65535]
recv(sock_fd, buf, sizeof(buf), 0)
...
首先可以肯定这是可以的。但是,仔细想想我们的网络程序可能是一个HTTP服务,可能是一个RPC服务,也可能是我们自己定义的某个协议。这个时候,就没法做到通用了,针对每一种协议都要写一遍上面的代码。这显然不利于扩展和维护。
有了Buffer之后,相当于是把数据读取和业务处理给分离开了。这样,不管上层业务怎么变,都只需要基于Buffer去实现就可以了。
在这个方法中,首先我们也是判断了指针r_idx和写指针w_idx不能重合,如果重合了,说明Buffer已经充满了。在上层业务中可以判断返回值等于-2的时候,就需要停下来先从Buffer把数据读出来处理了之后再从套接字去读取数据到Buffer中。
和Buffer填充数据一样,当读指针r_idx在写指针w_idx的右边的时候,读指针r_idx的右边是不能写数据的,因为数据还没被取走。此时,实际可写入的字节数是r_idx-w_idx。
当写指针w_idx到Buffer结尾的长度,不足以容纳BUFFER_SIZE的时候,实际写入的字节数是size-w_idx。注意,这里实际上size和BUFFER_SIZE是一样的。所以,大部分情况实际写入都是size-w_idx。
只有当size-w_idx等于BUFFER_SIZE的时候实际写入字节数是BUFFER_SIZE,一般在第一次读的时候才会出现。
上面的BUFFER_SIZE是在buffer.h中定义的一个宏,这里是65535字节,也就是64KB。
最后,在从套接字读数据的时候,是从data+w_idx的位置开始写数据,读取read_size个字节,这就是上面说的实际写入的字节数。
当读取的结果大于0的时候,相应的读指针也要加上读取的字节数。但要注意的是,我们实现的是环形Buffer,所以当读指针w_idx超过size的时候,要将w_idx置为0。表示,再次从0开始写入。
往套接字写
int buffer_write_to_socket(struct buffer *buf, int sock_fd) {
if (buf->size - buf->r_idx == buf->w_idx) {
return -2;
}
int write_size = 0;
int write_total = 0;
while(1) {
if (buf->size - buf->r_idx == buf->w_idx) {
break;
}
write_size = buf->size - buf->r_idx;
if (buf->r_idx < buf->w_idx) {
write_size = buf->w_idx - buf->r_idx;
}
int ret = send(sock_fd, buf->data + buf->r_idx, write_size, 0);
if (ret <= 0) {
return ret;
}
write_total += ret;
if (buf->r_idx < buf->size) {
buf->r_idx += ret;
} else {
buf->r_idx = 0;
}
}
return write_total;
}
搞明白了往Buffer里填充数据,和从套接字读取数据到Buffer之后,将Buffer往套接字写也就变得简单了。这里的代码你可以自己试着看一下。
唯一要注意的是,当写指针w_idx在读指针r_idx右边的时候,实际可读取的字节数是w_idx-r_idx。因为w_idx右边的是待写入的数据。可以理解为还没有数据。
资源释放
void free_buffer(struct buffer *buf) {
free(buf->data);
free(buf);
}
资源释放要注意的是,不能一上来就把buf给free了,因为buf中的data也是一个指针,如果先释放buf,那data就是一个野指针了,是没有机会被释放的。所以,应该是先释放buf->data,然后释放buf。
Buffer完整代码如下:
// buffer.h
#define BUFFER_SIZE 65535
struct buffer {
char *data; // bufer data
int r_idx; // read index
int w_idx; // write index
int size; // buffer size
};
struct buffer *new_buffer();
void buffer_free(struct buffer *buf);
int buffer_append(struct buffer *buf, char *data, size_t len);
int buffer_read_from_socket(struct buffer *buf, int sock_fd);
int buffer_write_to_socket(struct buffer *buf, int sock_fd);
// buffer.c
#include "unistd.h"
#include "stdlib.h"
#include "string.h"
#include "sys/socket.h"
#include "buffer.h"
struct buffer *new_buffer() {
struct buffer *buf = malloc(sizeof(struct buffer));
if (!buf) {
return NULL;
}
buf->data = malloc(BUFFER_SIZE);
memset(buf->data, 0, BUFFER_SIZE);
buf->size = BUFFER_SIZE;
buf->r_idx = 0;
buf->w_idx = 0;
return buf;
}
void buffer_free(struct buffer *buf) {
free(buf->data);
free(buf);
}
int buffer_append(struct buffer *buf, char *data, size_t len) {
if (buf->size - buf->r_idx == buf->w_idx) {
return 0;
}
size_t write_size = 0;
size_t write_total = 0;
while(1) {
if (buf->size - buf->r_idx == buf->w_idx || write_total == len) {
break;
}
if (buf->r_idx > buf->w_idx) {
write_size = buf->r_idx - buf->w_idx;
} else if (buf->size - buf->w_idx < len) {
write_size = buf->size - buf->w_idx;
} else {
write_size = len;
}
memcpy(buf->data + buf->w_idx, data, write_size);
if (buf->w_idx + write_size < buf->size) {
buf->w_idx += write_size;
} else {
buf->w_idx = 0;
}
write_total += write_size;
}
return write_total;
}
// if return is -2, it means that the buffer is full
int buffer_read_from_socket(struct buffer *buf, int sock_fd) {
if (buf->size - buf->r_idx == buf->w_idx) {
return -2;
}
int read_size = 0;
if (buf->r_idx > buf->w_idx) {
read_size = buf->r_idx - buf->w_idx;
} else if (buf->size - buf->w_idx < BUFFER_SIZE) {
read_size = buf->size - buf->w_idx;
} else {
read_size = BUFFER_SIZE;
}
int ret = recv(sock_fd, buf->data + buf->w_idx, read_size, 0);
if (ret > 0) {
if (buf->w_idx + ret < buf->size) {
buf->w_idx += ret;
} else {
buf->w_idx = 0;
}
}
return ret;
}
// if return is -2, it means that the buffer is empty
int buffer_write_to_socket(struct buffer *buf, int sock_fd) {
if (buf->size - buf->r_idx == buf->w_idx) {
return -2;
}
int write_size = 0;
int write_total = 0;
while(1) {
if (buf->size - buf->r_idx == buf->w_idx) {
break;
}
write_size = buf->size - buf->r_idx;
if (buf->r_idx < buf->w_idx) {
write_size = buf->w_idx - buf->r_idx;
}
int ret = send(sock_fd, buf->data + buf->r_idx, write_size, 0);
if (ret <= 0) {
return ret;
}
write_total += ret;
if (buf->r_idx < buf->size) {
buf->r_idx += ret;
} else {
buf->r_idx = 0;
}
}
return write_total;
}
到此,一个简单的读Buffer就完成了。然后,我们改造一下server.c的代码,抽象出了三个方法
// 处理HTTP请求
void request_with_buffer(int sock_fd);
// 处理HTTP返回
void response_with_buffer(int sock_fd);
// 处理HTTP连接入口
void on_http_request(int sock_fd);
其中,request_with_buffer代码如下:
void request_with_buffer(int sock_fd) {
struct buffer *buf = new_buffer();
buffer_read_from_socket(buf, sock_fd);
printf("%s\n", buf->data);
buffer_free(buf); // 别忘了释放Buffer
}
HTTP请求参数的处理,我们使用一个Buffer从套接字里读了一次,然后把读到的结果打印出来了。
在真实的开发中,调用一次数据可能是读不完的。这里数据的读取应该还是要放在一个while循环里。这里你可以自已把代码下载下来试着改写一下。response_with_buffer代码如下:
void response_with_buffer(int sock_fd) {
struct buffer *buf = new_buffer();
buffer_append(buf, "HTTP/1.1 200 OK\r\n", strlen("HTTP/1.1 200 OK\r\n"));
buffer_append(buf, "Host: 127.0.0.1:3000\r\n", strlen("Host: 127.0.0.1:3000\r\n"));
buffer_append(buf, "Content-Type: text/html; charset=UTF-8\r\n", strlen("Content-Type: text/html; charset=UTF-8\r\n"));
buffer_append(buf, "\r\n", strlen("\r\n"));
char *body = "<html><body><h1>This is My HTTP Server</h1></body></html>";
buffer_append(buf, body, strlen(body));
buffer_write_to_socket(buf, sock_fd);
buffer_free(buf); // 别忘了释放Buffer
}
在处理HTTP请示的response里,我们原来直接调用send方法的地方改成了buffer_append。
首先,我们声明了一个buf,然后将返回的数据填充到Buffer中,最后调用buffer_write_to_socket方法往套接字写数据。
你可能会有疑问。这里我们为什么要搞这么复杂,先把数据写到Buffer,再往套接字写呢?
和接收数据一样,这里也是为了避免多次调用send和write方法。当然,这里你也可以声明一个大的字符数组也能达到一样的效果。
封装成Buffer只是为了将和套接字的交互都封装起来,不用每次发送都直接去调用send和write方法。
上面的代码,其实不是很严谨,我们在往Buffer填充数据的时候,应该判断是否已经满了,如果满了就要停下来,先调用buffer_write_to_socket方法往套接字先写一部分。这里你可以自己试一下。最后,在on_http_request方法中,分别调用了request_with_buffer和response_with_buffer方法。如下:
void on_http_request(int sock_fd) {
request_with_buffer(sock_fd);
response_with_buffer(sock_fd);
close(sock_fd);
}
而,on_http_reqeust方法是在main方法每次accept出来一个连接的时候调用的,参数sock_fd,就是accept出来的客户端的套接字。
int main(int argc, char *argv[]) {
int sock_fd = create_sock();
struct sockaddr_in client_addr;
while(1) {
socklen_t cli_len = sizeof(client_addr);
memset(&client_addr, 0, sizeof(client_addr));
int fd = accept(sock_fd, (struct sockaddr *)&client_addr, &cli_len);
if (fd < 0) {
perror("accept error");
exit(1);
}
on_http_request(fd);
}
}
项目CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.15)
set(CMAKE_C_STANDARD 11)
project(buffer VERSION 1.0 LANGUAGES C)
add_executable(server server.c buffer.c)
然后我们将服务server跑起来,如下:
接着,我们在浏览器访问一下,如下:
控制台输出:
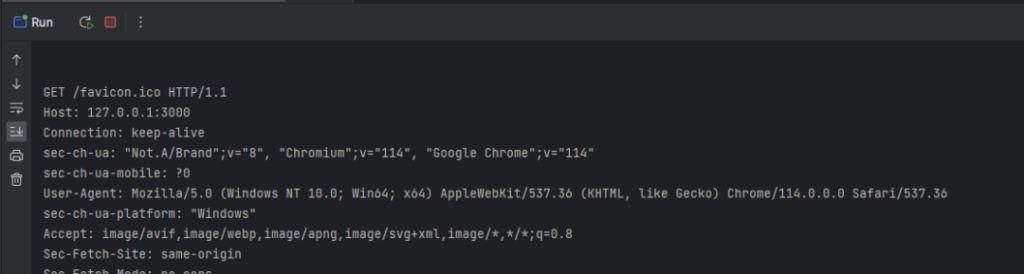
可以看到,通过我们自己实现的读写Buffer将我们在C语言最最最核心语法那篇文章里的迷你HTTP服务又跑起来了。
最终代码我打了一个tag,你可以自己去下载:v1.8
总结
对于,没有太多C语言基础的人来说,上面有些代码理解起来可能有些困难,比如:
int ret = send(sock_fd, buf->data + buf->r_idx, write_size, 0);
buf->data明明是一个指针,它怎么能做加法呢?这里加了一个buf->r_idx到底发生了什么?
由于本文的篇幅有限,没法照顾到C语言的语法知识,实际上这是C语言中指针的一些基本操作,如果觉得看不懂,还是得去补一下。
这里有个小建议,就是遇到不懂的就只去看不懂的,搞懂了之后立马回来。对于那些能大致看得懂的就不要去纠结了。如果有条件的话最好使用ChatGPT,可以在最少的交互次数中得到相对最精确的答案。
下一篇文章我们继续再深入一步,探索非阻塞套接字是怎么回事,大家加油!
作者:程序员班吉