今天,我们讲解多线程环境中的一种典型的性能问题,以及调优方式。
两个几乎一模一样的程序 #
test1.c #
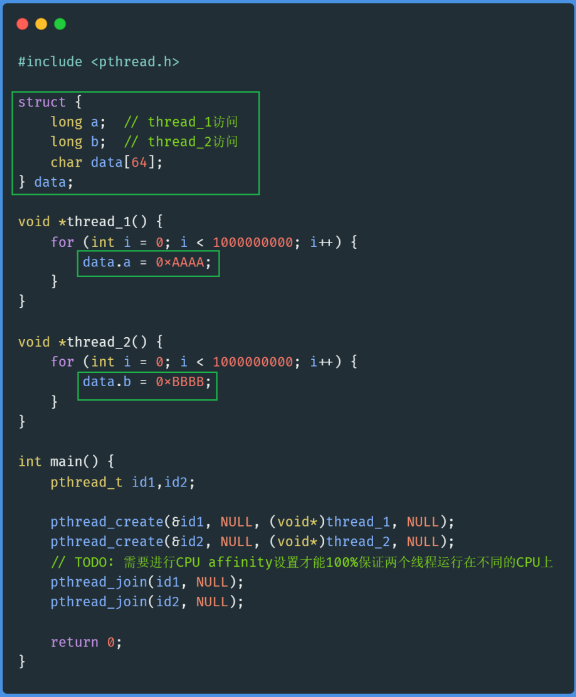
程序很简单,声明了一个结构体,并定义一个全局变量data,然后创建两个线程,thread_1给data.a字段赋值,thread_2给data.b字段赋值。
test2.c #
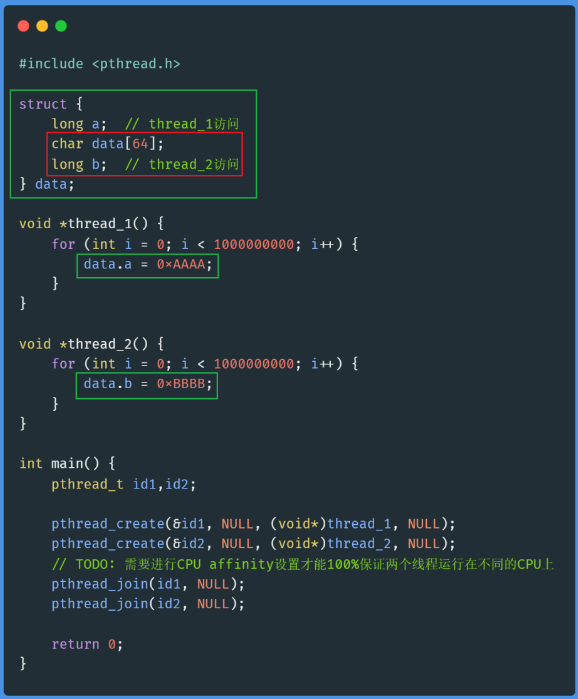
和test1.c唯一的区别是交换了结构体中字段b和字段data的位置。
不可思议的性能差异 #
现在分别编译运行test1.c和test2.c,并用time命令测量一下这两个程序的运行时间:
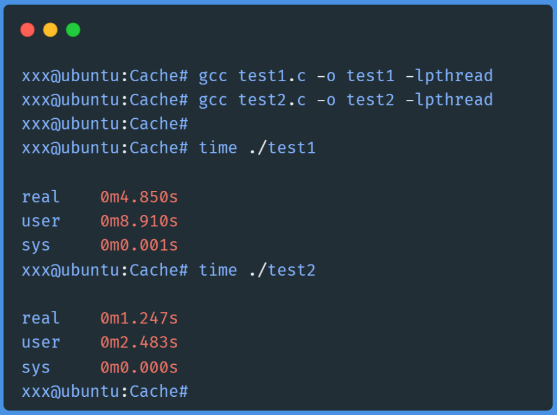
test1运行耗时4.85秒,test2运行耗时只有1.247秒,test1耗时居然是test2的四倍!
两个几乎一模一样的程序,就只是简单地交换了一下结构体中的两个字段,却有如此大的性能差异!
为什么?
重要说明 #
要想真正理解这个问题,必须要补充一些CPU底层的背景知识,尤其是Cache相关的知识,这是理解这个问题的关键所在。
在上一篇文章中,详细介绍了Cache的背景知识,并实例演示了,只修改一行代码,通过提高Cache的命中率,让程序耗时从10.3秒降到了0.5秒!对于没有Cache背景知识的同学,强烈建议先去看一下上一篇文章。
为了本文的完整性,并照顾没有Cache基础知识的同学,这里再简单介绍一下。如果你已经看过上一篇文章,可以直接跳到“多CPU系统上的Cache”这一小节继续阅读。
高速缓存 – Cache #
现代计算机中,为了解决内存访问速度和CPU计算速度严重不匹配的问题,在CPU和内存之间设计了高速缓存,即Cache。
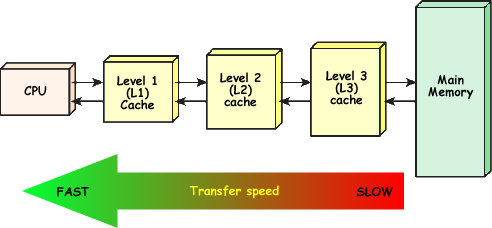
目前典型的CPU至少有三级Cache,CPU读取数据时,会在L1、L2、L3Cache中逐级查找,如果找到,就从Cache直接读取,找不到再从内存读取,并且把数据存放到Cache中,以便提高下次访问的效率。
在这个过程中,如果在Cache中找到所需数据,称为Cache命中(Cache Hit), 找不到称为Cache未命中(Cache Miss),Cache Miss时不得不从内存中读取,因此程序会遭受严重的性能惩罚。
Cache Line #
**Cache Line 是 Cache和内存之间进行数据传输的最小单位,典型的CPU Cache line大小是64个字节。**CPU在第一次访问一个地址的数据时,会把这个地址相邻的64个字节的数据一起加载到Cache中,这64个字节数据就位于同一条Cache Line上。
多CPU系统上的Cache #
在SMP(对称多处理器)系统中,每个CPU core都有自己的本地Cache。如下图所示:
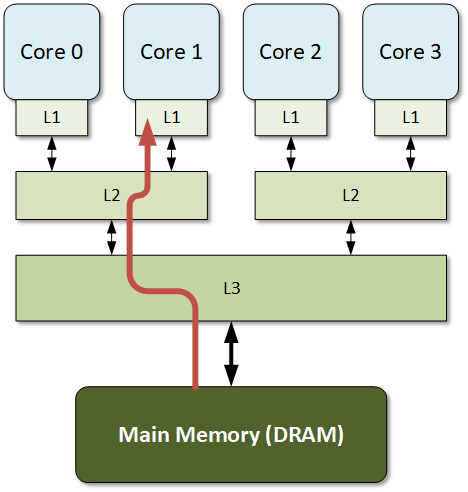
在上图中,每个CPU Core都有自己的独立的L1 Cache,Core 0和Core 1共享L2 Cache,Core 2和Core 3共享L2 Cache,而L3 Cache则是在所有的CPU core之间共享。
Cache一致性 #
因此,在多CPU系统上,同一个地址的数据,比如同一个变量,有可能在多个CPU的本地Cache中存在多份拷贝。既然同一数据存在多份拷贝,那么就必然存在数据一致性问题。
简单来说,就是必须要保证,在任意时间点,所有CPU看到的同一个地址的数据,必须是一样的。换言之,就是必须要保证每个CPU的本地Cache中的数据,能够如实反映内存中数据的真实的值。
假设内存中一个变量A = 1, 在core 0 和core 1的本地Cache中都有一份拷贝A0 = 1 和 A1 = 1。如果此时core 0需要修改变量的值,至少需要这些操作:
- 1. 在Core 0本地Cache中修改:A0 = 100
- 2. 把变量最新的值更新到内存中:A = 100
- 3. 通过某种方式,通知core 1。比如,把core 1本地的Cache的数据标记为无效,这样下次core 1从Cache访问A1的时候,发现数据已经无效,便会触发Cache Miss,重新从内存中读取最新的值,并把最新的值更新到本地Cache。
CPU为了保证Cache的一致性,实现了非常复杂的Cache一致性协议,感兴趣的童鞋可以去了解下MESI协议,这里不再赘述。
有了这些背景知识,下面开始讲解test1和test2为什么会有这么大的性能差异。
交换两个字段,到底影响了什么 #
test1.c和test2.c几乎一模一样:有两个线程,分别访问一个struct全局变量的两个不同字段。唯一的区别是:
test1.c中,字段a和b是相邻的:
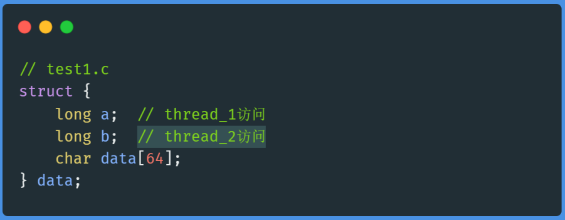
test2.c中,字段a和b是分开的:
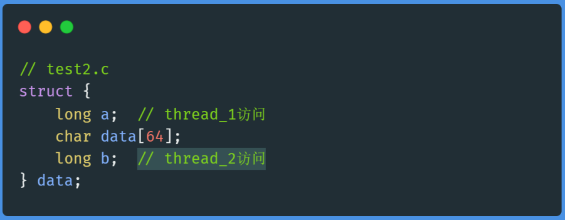
看起来,test1.c中两个字段a和b紧挨着的,按道理说,空间局部性应该更好,对吧?那为什么它的性能会比test2.c差那么多呢?
其实,这是由于CPU为了保证Cache的一致性,而引起的Cache伪共享问题!
Cache伪共享(Cache False Sharing) #
所谓Cache Line 伪共享,是由于运行在不同CPU上的不同线程,同时修改同一个Cache Line上的数据,导致对方Cache Line失效,从而引起频繁的Cache Miss。
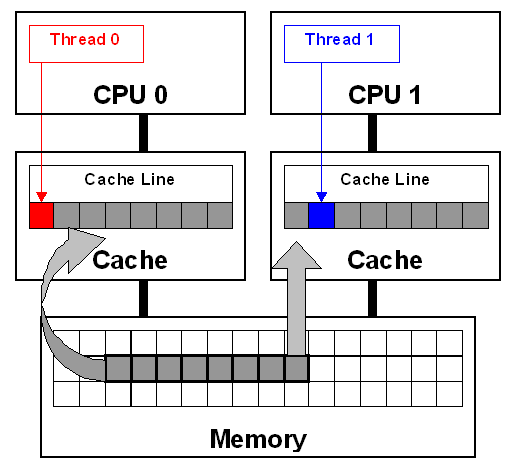
数据在Cache和内存之间传输是以Cache Line为单位的,所以,即便每个CPU各自修改的是不同的变量,但只要这些变量是在同一个Cache Line上的,那么一个CPU修改了这个Cashe Line之后,为了Cache一致性,必然会导致另外一个CPU的本地Cache中的同一个Cache Line无效,进而引发Cache Miss。
运行在不同CPU的多个线程,如果频繁修改位于同一个Cache Line上的数据(即便不是同一个地址的数据),必然会导致大量Cache Miss,严重降低程序性能。
性能差异的真正原因 #
再看一下两个程序代码:
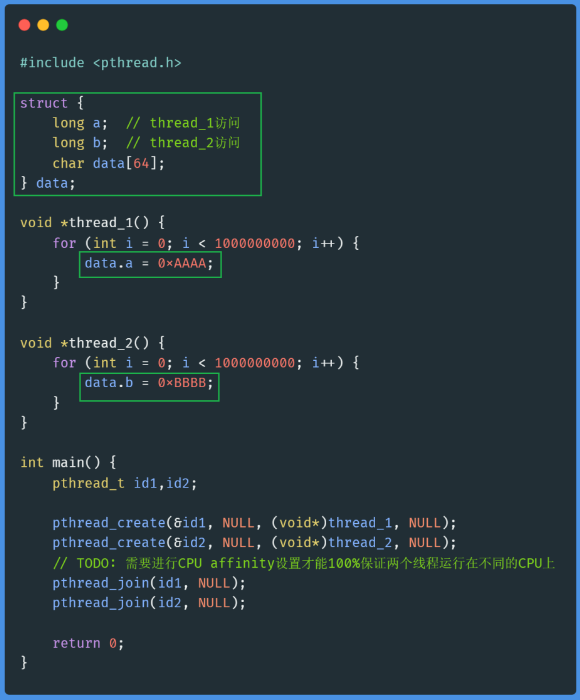
test1.c #
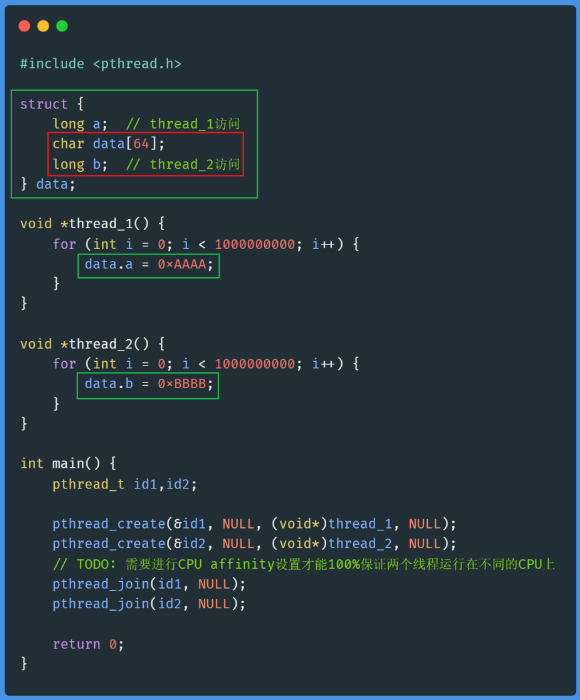
test2.c #
test1.c中,字段a和b在同一个Cache Line上,运行于不同CPU的两个线程同时修改这两个字段时,会相互导致对方CPU的本地Cache Line频繁失效,触发大量Cache Miss,从而性能非常差!
test2.c中,字段a和b中间隔了一个64字节的数组,从而确保了data.a和data.b分别处在不同的Cache Line上。如此一来,即便是两个线程同时修改这两个字段,但是他们是不同的Cache Line,也不会相互干扰,大大提高Cache命中率,甚至几乎不会出现Cache Miss,这就是为什么会有如此巨大的性能提升!
如何检测和避免Cache伪共享 #
在Linux上,可以使用perf c2c工具来检测和分析Cache伪共享的问题,篇幅所限,不再展开介绍,后续会有专门文章详细讲解perf的使用。
要避免Cache伪共享问题,最简单的方式是把不同线程频繁修改的数据放在不同Cache Line上,如本文例子中,在字段a和b之间填充了64个字节的数组,以此来保证两个字段一定位于不同Cache Line中。实际项目中,要根据具体场景进行分析、解决。