完美的循环 #
在开始之前,我们可以思考一下,什么样的循环是编译器需要的?或者说编译器会想要去生成什么样的代码呢?
一般来说,理想的循环有如下的特性:
- 只执行必要的工作,移除所有无关和不必要的计算;
- 应当使用最快的可使用指令来实现目标;也即循环内指令最少;
-
循环应尽量使用
SIMD指令;SIMD指令(Single instruction, multiple data)能够并行的处理多个数据,例如同时进行四个同类型变量的加法; -
指令应当尽可能平衡的使用
CPU单元;例如如果循环中的除法指令过多,就会导致整个循环在等待除法指令的执行从而成为性能瓶颈; - 循环内的内存访问模式应当尽可能好;好的访存模式能够带来好的性能;
这是编译器尝试去生成代码的目标,同样的,这些目标对于我们自己进行循环优化也有借鉴意义。
性能绊脚石 #
接着,我们需要了解,什么会影响编译器循环优化的效果。两个重要的因素是函数调用(function calls)和指针别名(pointer aliasing)。这是因为对于编译器而言,优化的前提是不影响代码的正确运行,这使得编译器在处理关键代码中的变量是常数或者比较独立的变量时会有比较好的优化效果,这个时候上下文更短,更能够进行判断和分析;然而在存在函数调用和指针别名的情况下,编译器很难判断做出激进的优化会不会影响代码的正确运行,因而编译器会选择保守的优化。
函数调用 #
函数调用成为性能绊脚石的原因是因为函数调用可能会改变内存的情况,例如如下的代码:
for (int i = 0; i < n; i++) {
if (debug) {
A;
printf("The data is NaN\n");
} else {
B;
}
}
这里debug变量可能是全局变量,也可能是堆上分配的变量,或者类的成员。在这些情况下,函数可能会修改debug的值。对于开发者而言,debug是否会变化是可以确定的,但是对于编译器而言是比较难确定的。如果编译器知道debug的值不会发生变化的话,编译器可以尝试将这个代码做如下优化:
if (debug) {
for (int i = 0; i < n; i++) {
A;
printf("The data is NaN\n");
}
} else {
for (int i = 0; i < n; i++) {
B;
}
}
如果能确定debug的值可以在编译时直接变成单循环。 然而,编译器并不知道这个
debug变量是否会发生变化,所以其会假设函数printf()可能会修改debug的值,因此,编译器不会像上面那样去进行优化。我们可以通过设置局部变量的方式让编译器了解到这个变量并不会发生变化:
bool debug_local = debug;
for (int i = 0; i < n; i++) {
if (debug_local) {
A;
printf("The data is NaN\n");
} else {
B;
}
}
由于是局部变量,所以不会在调用的函数中被修改,而其他的诸如全局变量、堆上变量等,可能会在函数中被修改。
此外,在有函数出现的情况下,编译器自身的优化能力就会下降。例如下面的例子:
double add(double a, double b) {
return a + b;
}
for (int i = 0; i < n; i++) {
c[i] = add(a[i], b[i]);
}
如果编译器能够将add函数进行内联,那么编译器就可以尝试做更多的优化;但是如果add函数无法被内联,编译器就只能进行标量版本的循环,每次都去调用add函数。而一旦涉及到函数的调用,就需要进行跳转,过多的跳转会影响到程序的性能。
可以通过LTO(Link Time Optimization)来进行优化。
指针别名 #
第二个影响性能的因素是指针别名(pointer aliasing)。在存在指针别名的情况下,编译器不能将数据存储在寄存器中,而必须将其存储在内存中。这导致了访存的低效。此外,指针别名也会影响循环矢量化。那么什么是指针别名呢?考虑如下的例子:
for (int i = 0; i < n; i++) {
b[i] = 0;
for (int j = 0; j < n; j++) {
b[i] += a[i][j];
}
}
在这个例子中,a和b在存储上没有关联,因而在内循环上可以进行一些优化(见后文)。然而如果a和b有一定关联,例如b指向的是a的一行,也即b[3]可能等于a[2][3],那么这时候编译器就不会进行优化,从而生成性能比较差的代码。
优化前-内联 #
在编译器开始优化你的代码前,编译器会先进行内联操作。内联是指将函数调用转换成编码的格式,例如前文提到的:
double add(double a, double b) {
return a + b;
}
for (int i = 0; i < n; i++) {
c[i] = add(a[i], b[i]);
}
可以将其内联成:
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}
内联自身是一个小的编译器优化,因为能够帮助我们减少调用函数的开销。内联更大的好处在于能够为编译器后续的优化提供基础。如果短函数定义与调用在同一文件中,编译器就会尝试去做内联操作。
基础优化 #
将变量维持在寄存器中 #
在计算机中,寄存器访存是最快的访存方式,因此如果我们能够尽可能的操作寄存器来存储变量,就可以提高访存的时间从而提高型男。
编译器有专门的寄存器分配器(register allocator)来进行寄存器的分配。由于CPU中寄存器的数量是有限的,编译器需要基于某些特征来判断哪些变量适合放在寄存器中,哪些变量适合放在内存里。
有两种情况会阻止编译器将变量存在寄存器中:
- 变量过多:如果在循环中我们有过多的未使用变量,编译器就无法将它们都存储咋寄存器中。因此寄存器需要考虑将部分暂时用不到的变量放在内存中,在需要的时候再将这个变量加载到寄存器中,这种现象称为寄存器溢出(register spilling)。
- 指针别名:如果存在指向标量A的指针B,那么我们可以通过直接修改A或者通过指针B来修改A的值。寄存器不会将A放在寄存器中,因为通过指针对其进行的修改将会丢失。针对这类标量的操作,都会遵循加载、修改、存储的流程进行修改。
这里修改丢失是因为如果通过指针修改了A的值,仍然会使用寄存器中存储的值去进行操作,这就导致了丢失现象的发生。 针对寄存器溢出现象,我们可以将循环拆分成多个循环来进行操作。那么我们该如何判断是否存在寄存器溢出现象呢?我们可以通过使用编译器优化报告来判断是否存在这种现象。
后续将有文章介绍编译器优化报告相关内容。 C和C++都有严格的别名机制,这意味着当循环中同时存在标量和指向标量的指针时,比如存在
int *p和int i时,除非我们能够保证p不会指向i,否则寄存器会假设p可能指向i从而将i存储在内存中。那么我们该如何让编译器知道变量不会被指针指向呢?对于全局变量、静态变量和类成员等,我们可以通过复制成局部变量来让编译器意识到该变量不会被指针指向和修改。
移除无关运算 #
在这个步骤,编译器的目标是尽可能的移除循环中无用的部分。
无用计算 #
有些计算并不需要,我们可以直接移除掉。如下所示:
void add(int* a, int* b) {
(*a)++;
if (b) (*b)++;
}
for (int i = 0; i < n; i++) {
add(&a[i], nullptr);
}
在编译器进行内联以后,由于传给add函数的参数int *b始终为nullptr,所以编译器可以直接移除掉这部分的判断:
for (int i = 0; i < n; i++) {
(*a)++;
}
在编译的过程中,编译器会尽可能的忽略掉不会执行的代码,也即所谓的死代码消除(dead code elimination)。
循环不变量 #
循环不变量(Loop invariant computation)是指在循环中需要,但是不需要每次都在循环中计算的部分。例如如下的代码:
for (int i = 0; i < n; i++) {
switch (operation) {
case ADD: a[i]+= x * x; break;
case SUB: a[i]-= x * x; break;
}
}
这个循环中,operation和x都是循环无关变量,因为他们不会随着循环的发生而改变。编译器会自动的计算出x*x的值,从而减少重复运算。只要编译器能够确定表达式是循环不变的,就会尽可能的进行这种优化。称为循环不变量代码移动(loop invariant code motion)。
当涉及到operation的部分,情况会稍微有一些复杂。因为operation的值决定了整个函数的控制流,针对这种情况,编译器会尝试对不同的控制流创建循环:
auto x_2 = x * x;
if (operation == ADD) {
for (int i = 0; i < n; i++) {
a[i] += x_2;
}
} else if (operation == SUB) {
for (int i = 0; i < n; i++) {
a[i] -= x_2;
}
}
这种转换成为循环分裂(loop unswitching)。与前者相反的是,编译器针对循环分裂采取比较保守的策略。随着判断变量的增多,循环分裂出来的代码也会指数级增长。
这两种优化的主要难点在于如何寻找循环不变量。在编译器无法进行准确的判断的时候,编译器往往偏向保守。
迭代器相关变量 #
迭代器相关变量(Iterator variable dependent computation)是指依赖于迭代器变量的值。如下所示:
for (int i = 0; i < n; i++) {
auto min_val = a[i];
if (i != 0) {
min_val = std::min(a[i - 1], min_val);
}
if (i != (n - 1)) {
min_val = std::min(a[i + 1], min_val);
}
b[i] = min_val;
}
两个判断条件都非常的依赖于迭代器i的值,它们并不依赖于循环中的数据。因此,我们可以将它们移出循环并进行特殊判断:
b[0] = std::min(a[0], a[1]);
for (int i = 1; i < n - 1; i++) {
auto min_val = a[i];
min_val = std::min(a[i - 1], min_val);
min_val = std::min(a[i + 1], min_val);
b[i] = min_val;
}
b[n - 1] = std::min(a[n - 2], a[n - 1]);
编译器比较少的进行这种优化。
使用更廉价(cheaper)的指令 #
编译器在生成代码时尽可能的生成总开销低的指令。常见的优化成为变量归纳(induction variables)。如下:
for (int i = 0; i < n; i++) {
a[i] = i * 3;
}
在循环中,i * 3的值随着迭代器i而变化,因此,与其每次都进行乘法计算,编译器尝试可以通过开销更低的加法运算实现:
tmp = 0;
for (int i = 0, int tmp = 0; i < n; i++) {
a[i] = tmp;
tmp += 3;
}
这在访问数组元素的情况下特别有用。例如我们有一个MyClass类,每次进行跨对象访问:
class MyClass {
double a;
double b;
double c;
};
for (int i = 0; i < n; i++) {
a[i].b += 1.0;
}
对于a[i].b,会被转换成(a+i*sizeof(MyClass)+8)。在这种情况下,编译器知道第一个元素是a + 8,下一个元素的地址偏移sizeof(MyClass),每次只需要采取加法计算新的地址,而不需要每次都进行乘法运算。
循环展开及相关优化 #
在做完前面提到的基础优化后,编译器进入到优化的下一阶段。下一阶段就是循环展开(loop unrolling)阶段。例如如下的代码:
for (int i = 0; i < n; i++) {
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
}
当这个循环迭代次数非常少的时候,循环操作本身的开销和循环内部操作的开销可能是一致的,在这种情况下,我们需要进行循环展开操作:
for (int i = 0; i < n; ) {
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
}
在这种情况下,我们提高了循环内部的工作量,相对减少了循环操作的开销。展开有两种好处,一是可以减少开销,二是可以让我们进行一些额外的优化。例如在上面的例子中,i/2和(i+1)/2在i是偶数的情况下一致,就可以删除一些不必要的负载:
for (int i = 0; i < n; ) {
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
store(a + i, b_val);
i++;
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
store(a + i, b_val);
i++;
}
在进行优化后,我们只需要进行两个load操作,而原来需要四次load操作。
此外,编译器在基本块级别上进行指令调度,进行循环展开可以增加基本块的大小,从而调高了指令调度的可能。随着基本块大小的增加,编译器可以更好地调度指令,目标是增加可用的指令级并行性,以更平衡的方式使用CPU资源等。
循环展开有如下的一些缺点:
-
循环展开增加了内存子系统的负载,特别是指令缓存和指令解码单元。指令缓存和数据缓存类似,容量是有限的,当循环内部过大的时候,会出现较多的缓存垃圾。循环的前半部分指令后续还会被用到,但是因为缓存容量的问题被丢弃,这样会产生
miss的情况。这会降低指令的取指译码速度,因此编译器在循环展开的时候会比较保守。 -
在现代
CPU上,循环开销可以忽略不急,因此,较为激进的编译器循环展开策略已经是过去式了。
在一些非常小的循环上,例如五次以内,编译器会直接展开成为指令而不是循环。
在编译器的早期,我们可以通过手动循环展开来获取性能收益,但是在现代编译器上,手动循环展开可能会阻碍其他的优化,可以将这部分工作交给更专业的编译器去做。例如我们可以通过pragma clang loop unroll factor(2)让clang进行两倍的循环展开。
循环流水(Loop pipelining) #
如果你对CPU流水线有一定了解,你会发现限制CPU运算速度的一个因素是指令依赖( instructions dependencies),如果有指令A和指令B,前者的结果是后者的原数据,那么这两者就存在依赖关系。例如:
for (int i = 0; i < n; i++) {
val_a = load(a + i);
val_b = load(b + i);
val_c = add(val_a, val_b);
store(val_c, c + i);
}
循环之中包含四条指令,load指令不存在依赖现象,但是add指令一定要等待load指令执行完才进行,同样的,store指令也需要等待add指令指令。这些依赖关系阻碍了CPU达到它的最佳吞吐状态,编译器采用一种称为循环流水线(loop pipelining)的技术来打破依赖链。
循环流水线有点类似于CPU中的流水线设计,将整体划分为了多个阶段,从而进行效率的提升。在这个例子中,我们可以将整个循环划分为三个模块:取值、计算和存储。在单循环中,我们可以取i + 2迭代的值,计算i + 1迭代以及存储i迭代:
val_a = load(a + 0);
val_b = load(b + 0);
val_c = add(val_a, val_b);
val_a = load(a + 1);
val_b = load(b + 1);
for (int i = 0; i < n - 2; i++) {
store(val_c, c + i);
val_c = add(val_a, val_b);
val_a = load(a + i + 2);
val_b = load(b + i + 2);
}
store(val_c, n - 2);
val_c = add(val_a, val_b);
store(val_c, n - 1);
我们聚焦于循环内部。可以看到,针对取值、计算和存储三个阶段,我们分别使用的是迭代i+2、i+1和i的值,这些值之间不存在任何的依赖关系,这样能让CPU更好的执行它们。和流水线类似,我们需要处理开始和结果部分,这部分的时间复杂度往往是常量的,可以忽略不计。
值得注意的是,在现代CPU中,由于乱序执行的存在,我们很难从循环流水线中取得性能优化。
向量化(Vectorization)和相关优化 #
在进行了前文的优化后,编译器应当已经得到了一个没有不必要计算、相对无依赖的简洁代码。然而,在许多情况下,可以通过向量化来提高速度。
向量化背后的基本思想是,CPU 中有特殊的向量寄存器,可以保存多个相同类型的值,例如同时对八个int进行加法运算,也就是我们常说的SIMD指令。SIMD也即Single instruction, multiple data,是计算机体系结构中费林分类法(Flynn’s Taxonomy)的一种。该方法针对指令和数据进行划分:
- 单一指令流单一资料流计算机(SISD)
- 单一指令流多资料流计算机(SIMD)
- 多指令流单一资料流计算机(MISD)
- 多指令流多资料流计算机(MIMD)
例如,针对如下的代码:
for (int i = 0; i < n; i+=4) {
double<4> b_val = load<4>(B + i);
double<4> c_val = load<4>(C + i);
double<4> a_val = add<4>(b_val, c_val);
store<4>(a_val, A + i);
}
如下图所示:
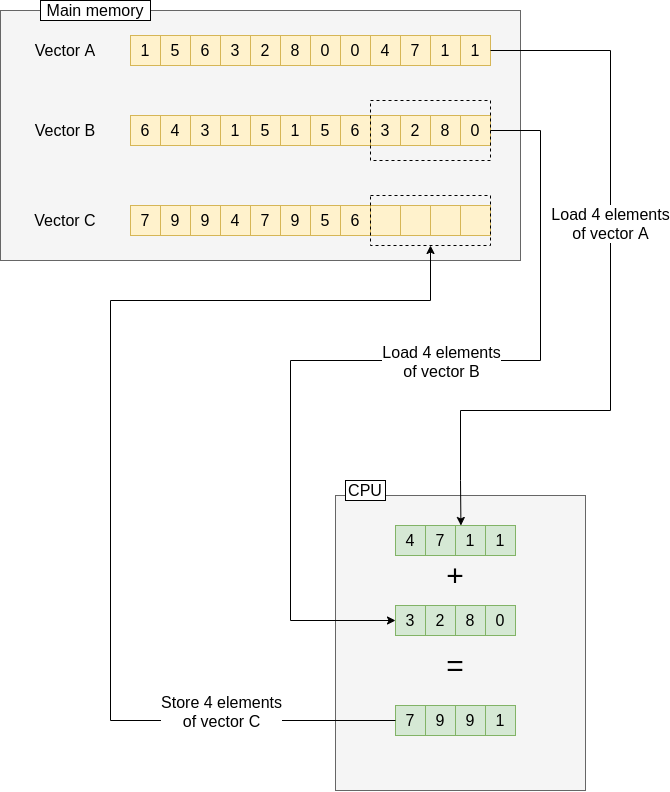
每次我们加载两组4个double的数据到向量计算器中,然后进行四个double的计算,最后一次写回。用的周期和单数据流一致,但是相对而言处理吞吐能力大大提升。
在选择了适当的开关后,编译器可以进行自动矢量化,成功的矢量化有以下前提:
-
类型简单:在简单类型上运行时,向量化会带来比较好的提升。这里说的简单不仅仅是内置类型如
char等,还可以是简单的类或者结构体,如struct complex { double re; double im;}; -
循环是顺序迭代的:正如我们前面例子里的那样,向量化是一批批连续的进行使用,因此如果中间有部分不使用就可能不太适合;此外,不是顺序迭代的情况可能会撞到内存墙(
memory wall),导致负收益; - 循环次数是一定的:循环的迭代次数必须得是可数的,例如从零到一万的迭代,而对于像获取字符串长度这样的循环,其迭代次数是不确定的;
-
没有循环依赖:每一次循环执行都是独立的,例如
A[i] = B[i] + C[i],而对于A[i] = B[i] + A[i-1]的情况则不太适用; -
在循环中不存在指针别名:如果两个指针指向或部分指向了内存的同一片区域,我们就认为这两个指针互为别名。例如
A[i] = B[i] + C[i]可以被向量化因为在A、B、C之间不存在指针别名;然而如果double * C = A - 1,在这种情况下,A[i] = B[i] + C[i]就变成了A[i] = B[i] + A[i-1],也就无法进行向量化了。如果你确定指针之间不存在别名的话,可以使用__restrict__关键词来告诉寄存器这里不存在别名,可以尝试进行向量化;
与向量化相关的小技巧 #
Reductions #
Reductions是一种将一组数据转换成一个数据的操作。假设我们现在正在计算数组之和:
double sum = 0.0;
for (int i = 0; i < n; i++) {
sum += a[i];
}
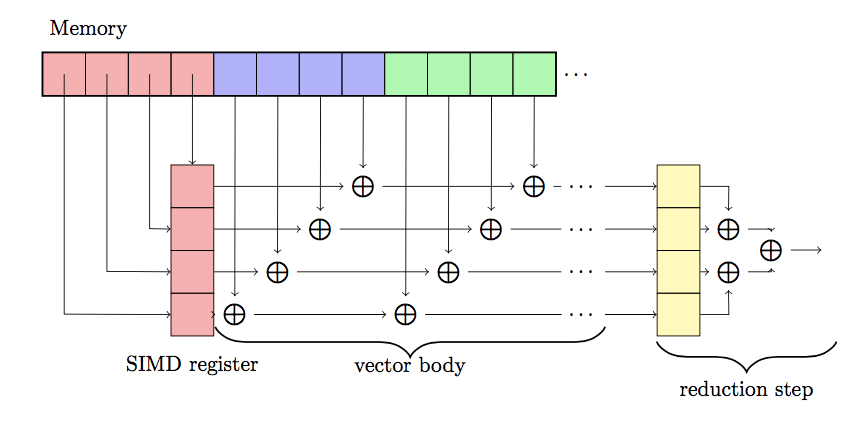
在这里向量化难以实现的原因是因为每次的计算都依赖于前一次的计算结果。我们可以通过Reductions来实现向量化。不同于只有一个sum结果,我们将每个向量都加和到到一个sum向量中。这样每一次向量操作都是单独的,最后我们只需要将一系列的sum加起来即可:
double<4> vec_sum = { 0.0, 0.0, 0.0, 0.0 };
for (int i = 0; i < n; i+=4) {
double<4> a_val = load<4>(a + i);
vec_sum = add<4>(a, vec_sum);
}
sum = 0.0;
for (int i = 0; i < 4; i++) {
sum += vec_sum[i];
}
如下图所示:
交错数据向量化 #
当数据连续存储的时候向量化能够很好的运行。但是实际情况中,我们经常会遇到交错的数据。例如实际上是结构体struct complex { double re; double im; },甚至在一些情况下,我们对结构体中内部的操作是不一致的,例如:
complex square(complex in) {
complex result;
result.re = in.re * in.re - in.im * in.im;
result.im = 2.0 * in.re * in.im;
return result;
}
如果我们将这样的结构体加载到向量寄存器,re和im是间隔排布的,且这两者的操作是不一致的。然而我们向量化往往是对一系列数据进行同样的操作,这里却是做不同的操作。为了能够对这样的循环进行向量化,我们需要将re和im分开保存。幸运的是,向量指令有提供解交错指令。我们可以通过解交错指令将re和im分割开,然后进行操作,操作完以后我们需要执行交错指令将数据进行恢复。
很少采用的优化 #
下面是一些编译器基本上不会使用的优化。
循环置换 #
循环置换(Loop Interchange)是尝试提升内存访问模式的优化方法,好的内存访问模型对程序的性能是非常重要的,考虑如下的代码:
for (int i = 1; i < LEN; i++) {
for (int j = 0; j < LEN; j++) {
b[j][i] = a[j][i] - a[j - 1][i];
}
}
这是局部性原理的一个经典例子,由于访问模式的不合理,将会出现大量的cache miss从而影响程序性能。在LLVM中,循环置换是一个实验性质的功能,可以通过-mllvm -enable-loopinterchange来打开。
循环拆分 #
循环拆分(Loop Distribution)是一个将复杂的循环拆分成多个简单循环的优化方法,考虑如下的例子:
for (int i = 0; i < n; i++) {
a[i] = a[i - 1] * b[i];
c[i] = a[i] + e[i];
}
a[i] = a[i - 1] * b[i]是不可以进行向量化的循环,而c[i] = a[i] + e[i]是可以进行向量化的循环,因此我们可以将其进行拆分:
for (int i = 0; i < n; i++) {
a[i] = a[i - 1] * b[i];
}
for (int i = 0; i < n; i++) {
c[i] = a[i] + e[i];
}
通过拆分成两个循环,我们可以让第二个循环进行向量化从而实现加速。
做循环拆分有两个理由:
- 确保向量化:通过拆分可以向量化的部分来提高性能;
- 避免寄存器溢出:通过拆分大循环成为小循环,可以减少寄存器溢出的概率;
值得注意的是,循环拆分是一个有争议的技术,因为它可能会带来性能的下降:我们进行了两次循环,这给内存带来了一些负载。
在LLVM中我们可以用-mllvm -enable-loop-distribute选项来开启,或者在程序中使用pragma clang loop distribute(enable)来声明。
循环合并 #
和循环拆分相反,循环合并(Loop Fusion)是一个将两个独立的循环合并的优化技术,考虑如下的例子:
// Find minimum loop
auto min = a[0];
for (int i = 1; i < n; i++) {
if (a[i] < min) min = a[i];
}
// Find maximum loop
auto max = a[0];
for (int i = 1; i < n; i++) {
if (a[i] > max) max = a[i];
}
第一个循环计算循环的最小值,而第二个循环计算循环的最大值,这两者互相独立,且循环操作是一致的,因此我们可以将合并到一起。
总结 #
在本文中,我们介绍了多种循环优化的方法。尽管编译器已经可以很智能的帮助我们做一些优化操作,我们仍然有必要去了解这些循环优化手段。
本文更多的在于介绍优化方法与思路,后续将会基于实际的代码进行更详细的讲解。